The Model Arena: Simplified
This article offers an explanation for the model selection processes within SensibleAI Forecast.
Key Terms
-
Model Suite: SensibleAI Forecast contains a suite of around 30 different baseline, statistical, and machine-learning models.
-
Error Metric: Metrics used to evaluate the accuracy of a model (mean squared error, mean absolute error, etc.)
-
Train Set: The portion of the training dataset that all selected model iterations for each target train and fit to.
-
Validation Set: The most accurate model iteration is selected for each target ~ model combination over this portion of training data. Predictions are made over the period and selection is based on the models whose predicted values have the lowest error metric score.
-
Test Set: The most accurate model ~ iteration combination is selected for each target on this portion of training data. Predictions are made over this period and selection is based on the models whose predicted values have the lowest error metric score.
-
Holdout Set: The portion of the training data reserved for optimal project selection. This data is withheld from the models to prevent data leakage.
-
Hyperparameter: A parameter set before the learning process begins, as it cannot be learned from the data. These parameters are tunable (hyperparameter tuning), directly controlling the training algorithm's behavior and significantly impacting the accuracy of the model being trained. They express "high-level" structural settings for algorithms. Different “tunings” of hyperparameters result in different model parameter optimizations, thus leading to different levels of accuracy.
Setting the Stage
To simplify and better understand the complexities of the model arena, we will use both the March Madness and Hunger Games analogies.
March Madness Analogy
Like a March Madness bracket, various models will compete head-to-head, with the winner advancing to the next round. However, winning is not determined by scoring the most points but by achieving the lowest evaluation error metric score. Finally, instead of crowning a single National Champion, we will declare a final “Model Champion” for every target.
The Hunger Games Analogy
The central area of the Hunger Games, where the competition takes place, is known as the Arena. The Arena features a wide range of environments, from forests and deserts to icy landscapes, each tailored to provide a challenging environment for the Tributes (participants) to battle and ultimately be the last standing in the games.
Different models (or tributes) are pitted against one another, each striving to outperform the others under various challenging conditions. These challenges might include adapting to unexpected fluctuations in data—similar to the unpredictable hazards in the Hunger Games arena—such as identifying and responding to significant spikes or dips caused by external events. Only the model that can best train, fit, and predict over historical data periods withheld from the models, will be left standing for that target.
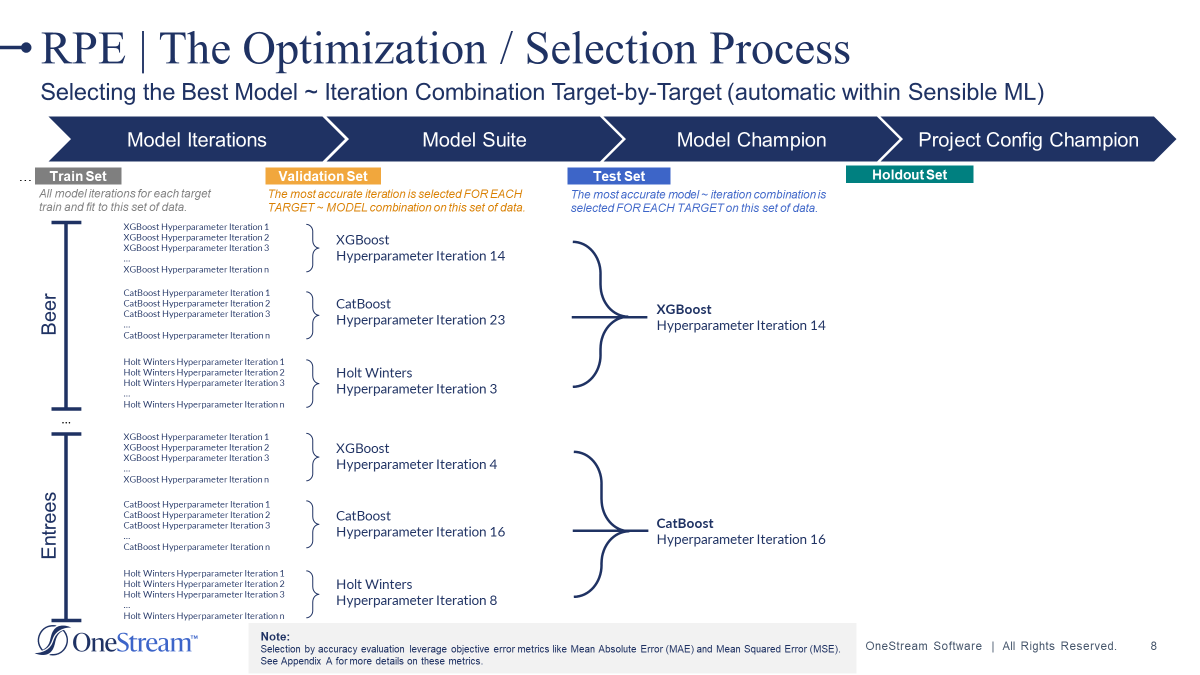
The Four Splits
During the pipeline job in SensibleAI Forecast, the target data is automatically split into four distinct segments by the Xperiflow engine:
- Train Set
- Validation Set
- Test Set
- Holdout set
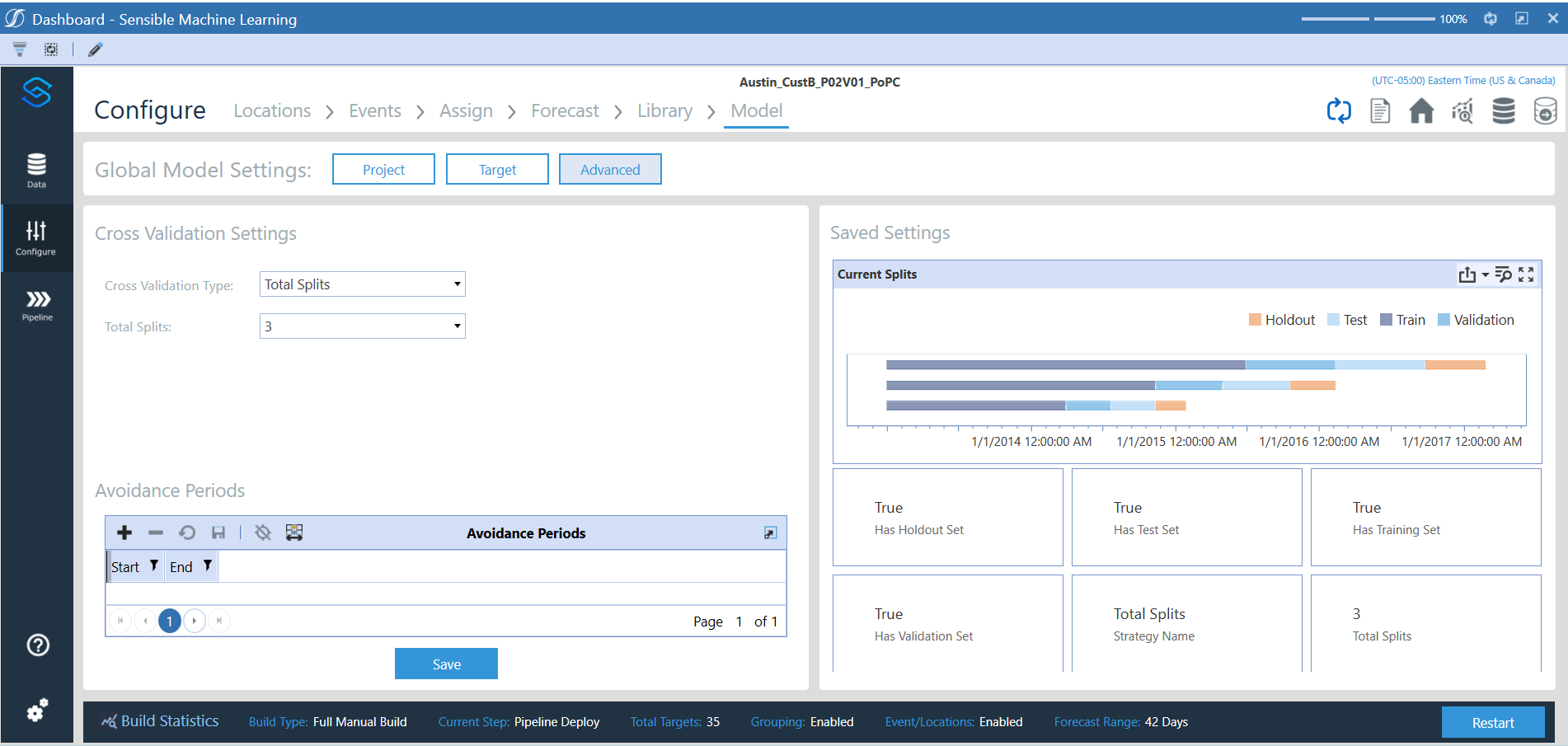
SensibleAI Forecast also provides users with the ability to manually configure these splits, allowing for customized data segmentation:
Please reference the chart below to understand what percentage of the historical target data is automatically allocated to each set.
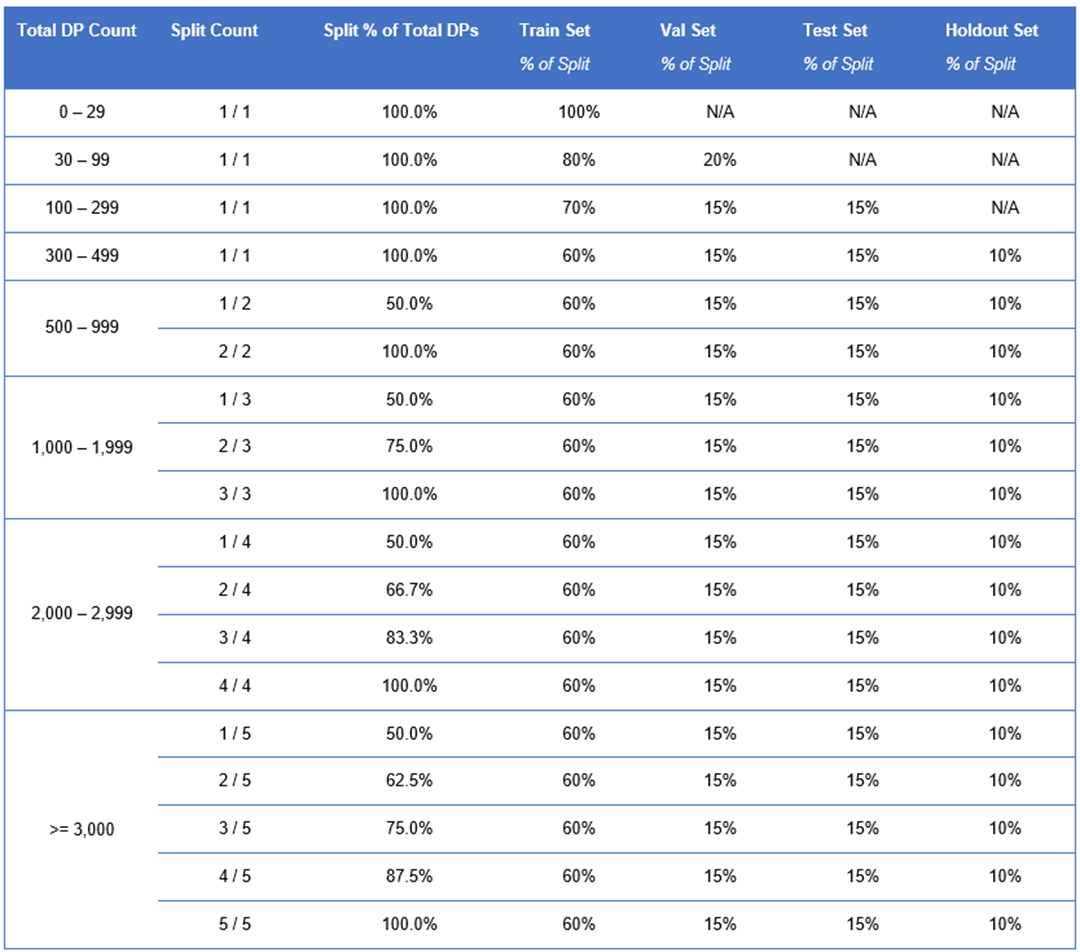
Expert Insight: A holdout set is only generated once the 300 data point threshold is reached.
The Model Arena
Let’s say that we have fed a year of daily-level historical data into SensibleAI Forecast for our models to train on. 60% of this dataset will be allocated to the train set, 15% to the validation set, 15% to the test set, and the remaining 10% will go to the holdout set. Now that our train dataset has been split up, the model selection process can begin.
Selecting the Models to Train
SensibleAI Forecast will inspect the number of data points present within the dataset along with the data patterns of a target to determine which models from the model suite should be trained on the data. Inspecting the data patterns includes determining whether there is seasonality or underlying trends that exist within the data. SensibleAI Forecast will only train models that match the structural data patterns of the data (SensibleAI Forecast Deep Dive Doc).
Expert Insight: When there is an insufficient amount of train data to evaluate model accuracy on, SensibleAI Forecast will prevent overfitting of the models. The Xperiflow engine will eliminate, or prune, models from being allowed to compete in the Model Arena based on the structural integrity of a particular target. More specifically, if the training dataset offers little to no repeated seasonality, the seasonal statistical models will be banned from running against that target in the Model Arena.
Train Set
Continuing with the previous example, various iterations of models inherent to the SensibleAI Forecast model suite will train and fit to the data present within the initial 60% of our training dataset. This phase involves a crucial step known as hyperparameter tuning. During hyperparameter tuning, adjustments are made to the models' parameters to find the optimal settings that will yield the best performance. This will significantly impact the accuracy of the model being trained.
When introducing the concept of hyperparameter tuning, leveraging the guitar analogy can be helpful.
Imagine hyperparameter tuning as the process of tuning a guitar. Each string on the guitar represents a different hyperparameter of the model. Just as a guitar player adjusts the tuning pegs to produce the correct note from each string, in hyperparameter tuning, you adjust the model's hyperparameters to improve performance. The goal is to find the perfect tuning (or set of hyperparameters) where the model performs at its best, much like achieving the perfect harmony in music.
Expert Insight:
- Hyperparameter tuning occurs on a model-by-model basis.
- Each model can reduce or augment its own hyperparameter search space based on other factors within the time series problem (time series data frequency, dataset length, sparsity, and more).
- These settings have been carefully selected by studying how each model generalizes with these hyperparameter search spaces through testing across multiple datasets in between SensibleAI Forecast release cycles.
- The hyperparameter tuning strategy utilized at the individual target-model level is “random” hyperparameter tuning.
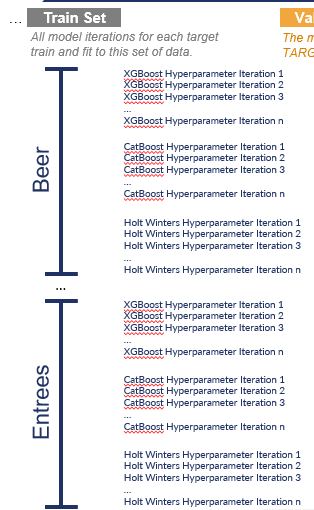
All model iterations that were selected to train and fit to this target’s data (as shown above), will now generate a prediction over the period present in the validation set (the next 15% of our historical target dataset).
Validation Set
At this point, the model iteration that achieved the lowest error metric score is selected as the winner of the validation round:
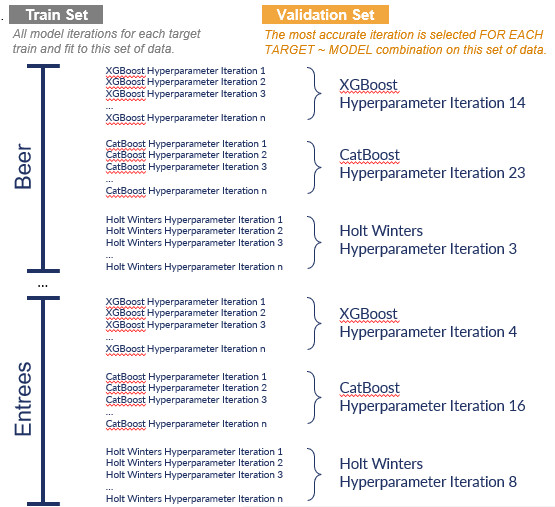
Now, we will repeat this same process and these winning model/iteration combinations will compete against each other.
The evaluation metric that is utilized to evaluate model performance is defined by the user within the Configure section Model step of SensibleAI Forecast:
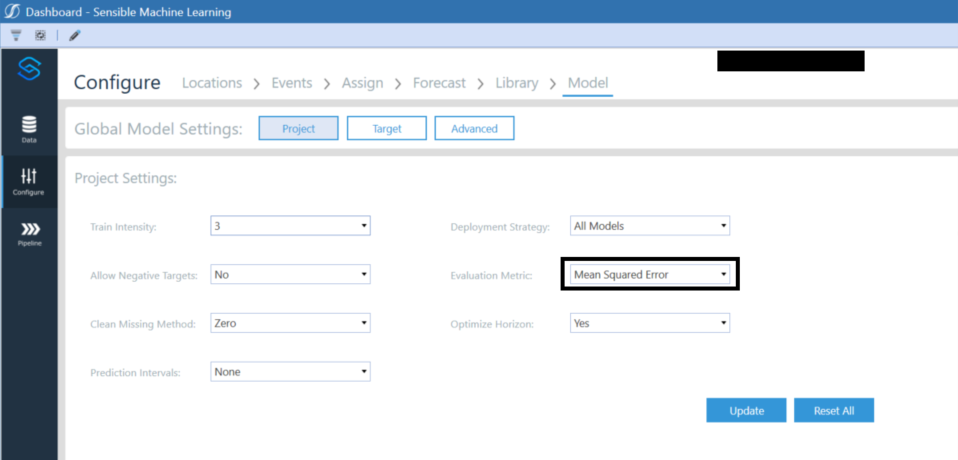
Model Project Settings
Test Set
From here, the selected model iteration combinations will generate a forecast over the next 15% of data allocated to our test set. Whichever model iteration combination has the forecasted values closest to the actual values present within the test set, will be the winner of the test round and can be crowned as the Model Champion for our target:
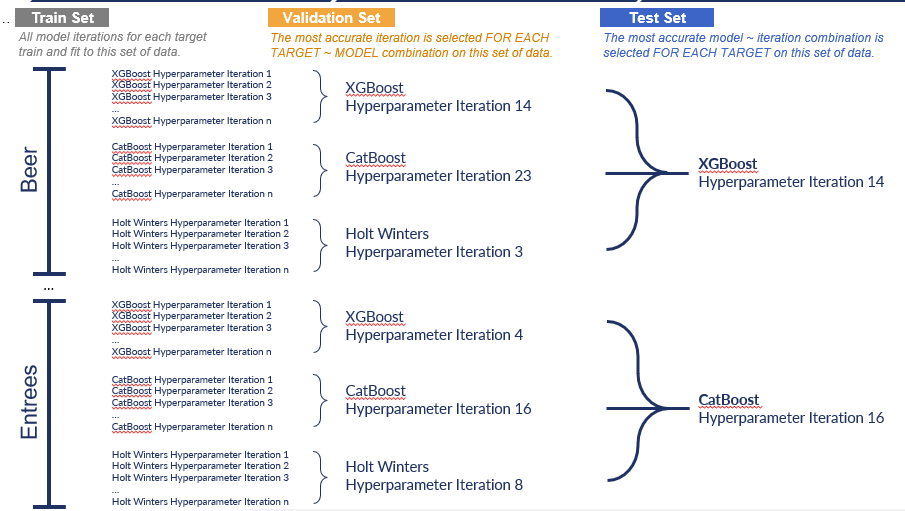
The Model Champion is identified as the model whose predicted values were closest to the actual values present within the Test Set (the model with the lowest error metric score). This model will be selected as our top model and will be deployed into production for each target.
Expert Insight: If the user sets ‘Optimize Horizon’ to ‘Yes’, the test portion of the largest split will be further split into smaller chunks equal to the forecast range (with a maximum of 10 chunks).
These chunks are used in the model selection stage to perform individual predictions on each chunk. This results in a better test of which model performs best on the given forecast range, also resulting in longer run times.
When running multiple projects with identical configurations and training data, different Model Champions may still be selected for the same target. This variation arises from the inherent randomness and variability associated with the hyperparameter tuning process.
A Target-by-Target Approach
It is important to highlight that many other machine learning solutions adopt a one-model-fits-all approach, applying a single model across all targets in their portfolio. For example, the Cat Boost Hyperparameter Iteration 16 model would have been selected as the model champion for Entrees AND Beer. This approach leads to significant compromises in accuracy, as it fails to identify and utilize the most accurate models for each target.
In contrast, SensibleAI Forecast allows the user to get very granular and select the most optimal models on a target-by-target basis. This approach ensures we capture the highest amount of accuracy that many other solutions simply cannot achieve.
Check out the following article on the Model Arena written by OneStream: https://www.onestream.com/blog/the-battle-of-models-sensible-machine-learning-improves-fpa-accuracy/